The Complete Guide to RAG Evaluation
Introduction
Evaluating RAG (Retrieval-Augmented Generation) applications presents unique challenges that go beyond standard LLM evaluation. The fundamental difficulty lies in assessing a system where quality depends on two interdependent components: retrieval and generation. Traditional approaches struggle with this complexity, often requiring expensive manual labeling of both ideal answers and relevant chunks, while still failing to provide reliable, consistent metrics.
This guide explores modern evaluation methodologies, including both established approaches and emerging techniques that address these challenges. We’ll examine traditional methods, their limitations, and newer approaches like generative reward models that aim to provide more consistent, trustworthy evaluation.
The RAG Evaluation Challenge
Existing RAG evaluation approaches face several critical limitations:
- Dependence on Ground Truth Labels: Traditional methods require manually labeled datasets specifying both the ideal answer and which chunks should be retrieved. This labeling process is expensive, time-consuming, and often impractical for real-world applications with evolving knowledge bases.
- Component Interdependence: RAG systems exhibit multiplicative quality relationships - excellent retrieval can’t compensate for poor generation, and vice versa. Most evaluation frameworks fail to properly assess this interdependence.
- LLM-as-Judge Limitations: A common approach uses LLMs to evaluate other LLMs, but this introduces several problems:
- Inconsistent Scoring: The same response might receive different scores across evaluations (e.g., 0.7 one time, 0.5 the next), making it difficult to track improvements reliably
- Complex Prompt Engineering: Achieving even moderate reliability requires extensive optimization of evaluation prompts and scoring rubrics
- Computational Cost: Running large LLMs for evaluation can be expensive and slow at scale
- Lack of Interpretability: Understanding why a particular score was given often requires additional analysis
These limitations become particularly problematic when teams need to make confident deployment decisions or demonstrate quantitative improvements to stakeholders.
Generative Reward Models: An Alternative Approach
One emerging solution to LLM-as-judge limitations is the use of generative reward models. These models are specifically trained to evaluate text quality and can provide more consistent, deterministic scoring. Key advantages include:
- Deterministic Scoring: The same input consistently produces the same score, enabling reliable A/B testing and progress tracking
- Simple Criteria Definition: Instead of complex prompts, evaluation criteria can often be defined in a single sentence
- Better Correlation: Purpose-built evaluation models can achieve higher correlation with human preferences and business metrics
- Efficiency: Smaller, specialized models can evaluate faster and more cost-effectively than general-purpose LLMs
For example, Composo’s generative reward model approach has demonstrated 89% agreement with expert preferences compared to 72% for traditional LLM-as-judge methods, while providing completely deterministic scoring.
Framework Overview
Whether using traditional LLM judges, generative reward models, or other approaches, a comprehensive RAG evaluation framework should assess both components independently and their interaction:
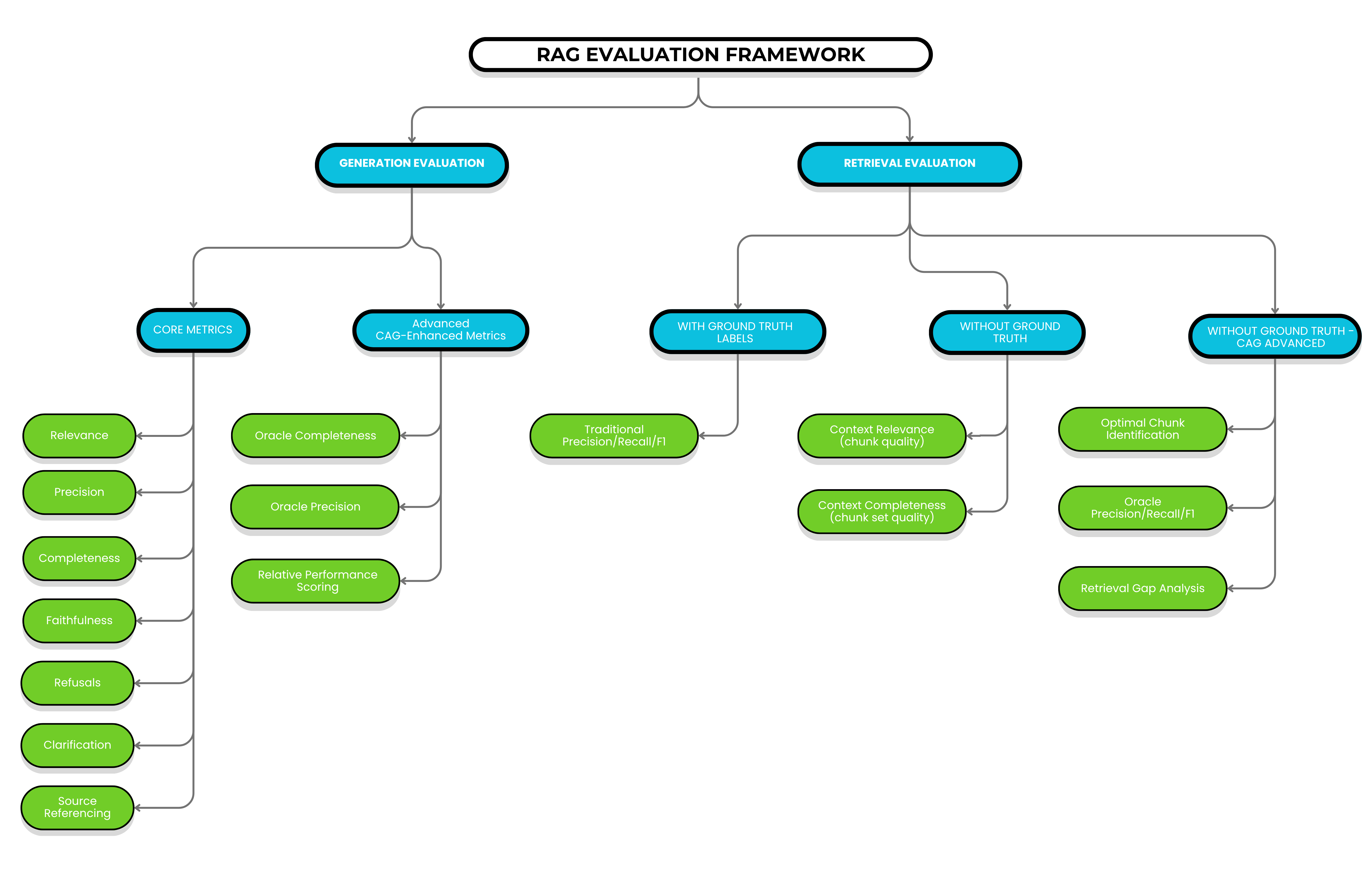
Part 1: Generation Evaluation
Generation evaluation assesses how effectively your LLM transforms retrieved context into high-quality answers. This evaluation can be performed independently of retrieval quality, making it an ideal starting point for RAG system assessment.
These metrics can be applied without any ground truth labels. The key question is how to actually assess these criteria in practice.
- Option 1: LLM-as-Judge:
- Use a frontier LLM (like GPT-4 or Claude) with carefully crafted prompts
- Challenges: Unreliable, produces inconsistent, imprecise scores, expensive at scale, requires significant prompt engineering to work well
- Example prompt might be ~50 lines defining scoring rubrics, examples, and edge cases
- Option 2: Generative Reward Models:
- Use purpose-built evaluation models that require only simple criteria
- Benefits: Precise, deterministic scoring, simple single-sentence criteria, better correlation with human judgment
For production systems where consistent measurement is critical, generative reward models provide the most reliable approach. Here’s how each metric works:
1. Relevance
Measures how much of the answer directly addresses the user’s question.
Example Criterion for Reward Models:
"Reward responses where all content directly addresses and is relevant to answering the user's specific question"
Why it matters: This metric identifies responses that include tangential information or fail to focus on what the user actually asked. It’s particularly important for user experience, as irrelevant information can obscure the actual answer.
2. Precision
Ensures the response contains only information necessary to answer the question, without superfluous details from the source material.
Example Criterion:
"Reward responses that include only information necessary to answer the question without extraneous details from the source material"
Why it matters: Precision evaluation helps identify verbose responses that may technically be correct but overwhelm users with unnecessary information. This is especially critical in professional contexts where concise, focused answers are valued.
3. Completeness
Verifies that all necessary information from the source material is included in the answer.
Example Criterion:
"Reward responses that comprehensively include all relevant information from the source material needed to fully answer the question"
Why it matters: Completeness ensures your system doesn’t omit critical details available in the retrieved context. This metric often reveals issues with context window management or prompt design that cause important information to be overlooked.
4. Faithfulness
Confirms the response contains only claims supported by the source material, without hallucination.
Example Criterion:
"Reward responses that make only claims directly supported by the provided source material without any hallucination or speculation"
Why it matters: Faithfulness is perhaps the most critical metric for production RAG systems. Hallucinations can severely damage user trust and create liability issues, making this evaluation essential for any deployment.
5. Refusals
Evaluates whether the system appropriately refuses to answer when lacking sufficient information.
Example Criterion:
"Reward responses that appropriately refuse to answer when the source material lacks sufficient information to address the question"
Why it matters: Proper refusal behavior prevents the system from generating plausible-sounding but incorrect answers when information is genuinely unavailable. This metric is crucial for maintaining system reliability.
6. Clarification
Assesses the system’s ability to identify ambiguous queries and request clarification.
Example Criterion:
"Reward responses that identify ambiguity in the question and request specific clarification needed to provide an accurate answer"
Why it matters: Clarification capabilities improve user experience by preventing misunderstandings and ensuring the system provides what users actually need.
7. Source Referencing
Verifies appropriate citation of source materials in responses.
Example Criterion:
"Reward responses that explicitly cite or reference the specific source documents or sections used to support each claim"
Why it matters: Source referencing enables users to verify information and builds trust in the system’s responses. It’s particularly important in domains requiring accountability and traceability.
8. Custom domain-specific criteria
Adapt or add to the above evaluation criteria with ones that are completely tailored to your application’s domain & use case.
For example:
"Reward responses that only use local medical guideline information when providing treatment recommendations"
"Reward responses that provide verbatim citations of relevant legal precedents when asked to generate legal content"
Part 2: Retrieval Evaluation
Retrieval evaluation assesses the quality of chunks selected from your knowledge base. The challenge here is determining what constitutes “good” retrieval without expensive manual labeling.
1) Traditional Approach (With Ground Truth Labels)
If you have invested in creating labeled data specifying which chunks should be retrieved for each query, you can calculate traditional metrics:
- Precision: What fraction of retrieved chunks are in the ground truth set
- Recall: What fraction of ground truth chunks were retrieved
- F1 Score: Harmonic mean balancing precision and recall
While these metrics are absolutely the gold standard & provide clear quantitative assessment, the cost and effort of maintaining labeled datasets often makes this approach impractical for production systems with evolving knowledge bases. The need to manually identify and label relevant chunks for each query creates a significant bottleneck, especially as knowledge bases grow and change over time.
2) Retrieval Evaluation Without Ground Truth Labels
When ground truth labels aren’t available — which is the reality for most production systems — we can still evaluate retrieval quality through the following two metrics.
Context Relevance
Evaluates individual chunks for their relevance to the query.
Example Criterion:
"Reward chunks that only contain information directly relevant to answering the user's question"
This metric helps identify retrieval systems that return partially relevant or tangentially related content. By evaluating each chunk independently, you can identify patterns in retrieval failures and optimize accordingly. Common issues revealed by context relevance evaluation include:
- Embedding models that don’t understand domain-specific terminology
- Chunk boundaries that split relevant information
- Query processing that doesn’t properly handle user intent
Context Completeness
Assesses whether the retrieved chunk set collectively contains all necessary information.
Example Criterion:
"Reward chunk sets that collectively contain all information needed to fully answer the question"
Context completeness evaluation reveals whether your retrieval system is finding all relevant information or consistently missing important pieces. This often highlights issues with:
- Top-k settings that are too restrictive
- Embedding spaces that cluster related but distinct concepts
- Reranking algorithms that prioritize relevance over comprehensive coverage
Together, these metrics provide valuable insights into retrieval quality without requiring any manual labeling effort. Similar to generation evaluation, you have two options for how to actually measure these:
LLM-as-Judge Approach:
- Prompt an LLM to score each chunk’s relevance to the query
- Issues: Expensive when evaluating many chunks, inconsistent scoring, requires careful prompt design
- May need different prompts for different domains or chunk types
Generative Reward Model Approach:
- Use specialized models with simple criteria & precise, deterministic scoring for consistent evaluation
- Benefits: High accuracy & precise quantification of chunk quality, fast evaluation of many chunks, deterministic results, domain-agnostic criteria that don’t require extensive prompt engineering
Part 3: Advanced Evaluation (Using CAG as an Oracle)
Understanding CAG (Cache-Augmented Generation)
Cache-Augmented Generation represents a paradigm shift in how we approach RAG evaluation. Instead of relying on limited retrieved chunks, CAG loads entire knowledge bases into the KV cache of a large-context LLM, enabling it to access all available information when generating responses. The latest large models we work with have context windows of 1m tokens which equates to ~3k A4 pages of text (or the entire Harry Potter book series).
The Theory Behind CAG Evaluation
Effective automated evaluation requires the evaluator to have some form of leverage over the system being evaluated. This leverage can come from several sources:
- Information Advantage: The evaluator has access to more information than the generator (traditional ground truth labels or, in CAG’s case, the complete knowledge base versus limited chunks)
- Computational Resources: The evaluator can invest more time, tokens, or computational power than would be practical in production (CAG’s large context processing)
- Focused Evaluation: The evaluator can concentrate on a single quality dimension rather than balancing multiple objectives
- Hindsight Analysis: The evaluator can assess decisions after seeing their outcomes
CAG leverages primarily the first two advantages - providing complete information access and investing additional computational resources to establish ground truth baselines.
Why CAG Answers Can Surpass Chunk-Based Generation
A critical insight about CAG is that answers generated with full document access can be fundamentally superior to those generated from even perfectly selected chunks. This superiority stems from several factors:
- Cross-Document Context: CAG can synthesize information from across entire documents, understanding relationships and dependencies that span multiple sections. Traditional chunk-based retrieval often breaks these connections, leading to incomplete or miscontextualized answers.
- Implicit Information: Documents often contain implicit relationships and context that become clear only when viewing the complete text. CAG captures these nuances that chunk boundaries inevitably destroy.
- Optimal Information Selection: With full visibility, CAG can identify and utilize the most relevant information regardless of how it’s distributed across the document, rather than being constrained by predetermined chunk boundaries.
CAG-Enhanced Retrieval Evaluation
CAG transforms retrieval evaluation by providing oracle ground truth. Here’s how the process works:
- Full Context Loading: Your entire knowledge base (up to 256k tokens) is loaded into a large-context model’s KV cache
- Optimal Chunk Identification: Given a query, CAG identifies which passages would ideally be retrieved
- Comparative Analysis: Your actual retrieved chunks are compared against CAG’s optimal selection
This approach enables several powerful analyses:
- Oracle Precision/Recall/F1: Calculate traditional metrics using CAG-identified optimal chunks as oracle ground truth. This provides the benefits of labeled data without the manual effort, with the CAG system acting as an all-knowing oracle.
- Retrieval Gap Analysis: Identify specific information that should have been retrieved but wasn’t, revealing systematic weaknesses in your retrieval strategy.
- Chunk Quality Distribution: Understand whether retrieval failures stem from embedding quality, reranking errors, or fundamental issues with your chunking strategy.
CAG-Enhanced Generation Evaluation
Perhaps the most powerful application of CAG is creating ground truth answers for generation evaluation. This process provides unique insights:
- Generate Oracle Baseline: CAG produces the best possible answer given complete information access, serving as an oracle with perfect knowledge
- Comparative Evaluation: Your RAG-generated answer is evaluated against this baseline
- Multi-Dimensional Analysis: Assess completeness, precision, and accuracy relative to ideal performance
This enables several advanced metrics:
- Oracle Completeness Score: Quantify what percentage of important information from the oracle CAG answer appears in your RAG response. This goes beyond simple completeness checking against retrieved chunks to measure completeness against the theoretically optimal answer provided by an all-knowing oracle.
- Oracle Precision Score: Identify superfluous information in your RAG answer that doesn’t appear in the focused oracle response, revealing generation inefficiencies when compared to perfect information processing.
- Relative Performance Index: Express your RAG system’s performance as a percentage of oracle performance, providing an intuitive metric for stakeholders and enabling clear tracking of improvements against the theoretical optimum.
- Enhanced Faithfulness Verification: Verify faithfulness against both the oracle answer and the complete document context, catching subtle hallucinations that chunk-based verification might miss.
Implementation Guide
Starting with Core Evaluation
Before implementing advanced CAG techniques, establish baseline performance:
- Deploy Generation Metrics: Implement the generation metrics using your chosen evaluation approach. With generative reward models, this requires only simple single-sentence criteria and provides immediate insights.
- Assess Retrieval Quality: Apply context relevance and completeness metrics to understand current retrieval performance & chunk quality without manual labelling.
- Identify Priority Issues: Use these initial metrics to identify whether retrieval or generation represents your primary bottleneck.
- Iterative Optimization: Make targeted improvements based on metric feedback. With deterministic scoring approaches, you can reliably measure the impact of each change.
Advancing to CAG-Enhanced Evaluation
Once you’ve established baselines and addressed obvious issues, CAG evaluation provides deeper insights:
- Prepare Your Knowledge Base: Organize your documents for CAG processing, potentially using intelligent sharding for bases exceeding context limits.
- Generate Oracle Baselines: Create oracle answers and optimal chunk sets for a representative sample of queries using CAG’s complete information access.
- Comprehensive Comparison: Evaluate both retrieval and generation against CAG baselines to identify improvement opportunities.
- Performance Tracking: Express performance as a percentage of oracle optimum, providing clear metrics for stakeholder communication.
Best Practices for Production Deployment
- Sampling Strategy: Rather than evaluating every query, use intelligent sampling to monitor system performance efficiently while controlling costs.
- Metric Stability: Choose evaluation approaches that provide consistent scoring across time and system changes. Deterministic methods enable more confident decision-making.
- Failure Analysis: When metrics indicate problems, focus in on these with targeted tests and potentially more advanced methods to diagnose where the issues are.
- Continuous Improvement: Establish regular evaluation cycles, using trends & relative changes in metrics to guide optimization efforts.
Additional Considerations
Domain-Specific Adaptations
Different domains require tailored evaluation approaches while maintaining simplicity:
- Healthcare: Emphasize faithfulness and refusal metrics, with criteria like “Reward responses that refuse to provide diagnoses or treatment recommendations beyond the provided documentation.”
- Legal: Focus on faithfulness, source referencing and precision, using criteria such as “Reward responses that cite specific sections, clauses, or precedents for every legal claim made.”
- Customer Support: Prioritize relevance, faithfulness and clarification, with criteria like “Reward responses that directly address the customer’s specific issue without including unrelated troubleshooting steps.”
Scaling Considerations
As your knowledge base grows, consider these strategies:
- Intelligent Sharding: Divide large document sets into semantically coherent shards for CAG processing, ensuring each shard maintains necessary context.
- Hierarchical Evaluation: Use lightweight metrics for routine monitoring and CAG evaluation for periodic deep analysis or when investigating specific issues.
- Oracle Dataset Creation: Use CAG as an oracle to generate high-quality question-answer pairs for your specific domain, creating reusable evaluation sets based on perfect information access.
Choosing Your Evaluation Approach
When selecting evaluation methods, consider:
- Consistency Requirements: If you need deterministic scoring for reliable A/B testing and progress tracking, generative reward models offer significant advantages over LLM judges.
- Resource Constraints: Balance evaluation quality with computational costs. Reward models can offer better efficiency for high-volume evaluation.
- Domain Specificity: Some domains may benefit from specialized evaluation models trained on relevant data.
- Scale: High-volume applications particularly benefit from efficient, specialized evaluation models.
- Integration Complexity: Consider how easily different approaches integrate with your existing infrastructure and workflows.
Conclusion
Effective RAG evaluation requires moving beyond traditional approaches that depend on expensive manual labeling or inconsistent LLM judges. Modern approaches, including generative reward models and innovative techniques like CAG, provide the comprehensive, reliable metrics needed for production confidence.
The key is selecting evaluation methods that provide:
- Consistent, reproducible scores for tracking improvements
- Good correlation with actual user satisfaction and business metrics
- Practical implementation without excessive complexity
- Flexibility to evaluate multiple quality dimensions
By evaluating generation and retrieval separately while understanding their interaction, you can identify specific improvement opportunities and track progress reliably. Whether using traditional methods, generative reward models, or advanced techniques like CAG, the goal remains the same: achieving consistent, high-quality performance that translates to real-world success.
Remember that evaluation is not a one-time activity but an ongoing process. As your RAG system evolves and your knowledge base grows, continuous evaluation with reliable metrics ensures your application maintains the quality your users expect.
Frequently asked questions
What is RAG evaluation?
RAG (retrieval-augmented generation) evaluation is the practice of measuring the quality of a RAG pipeline - both the retrieval step (did we fetch the right context?) and the generation step (did the model use the context correctly?). It is harder than generic LLM evaluation because quality depends on two interdependent components.
Why do RAGAS metrics correlate poorly with real hallucination rates?
RAGAS and similar statistical metrics are averages that can be high while individual outputs are wrong. They also do not know about your domain-specific definition of faithfulness. A custom evaluator with dedicated accuracy criteria - faithfulness, completeness, precision, appropriate refusals - tracks real quality much better.
What is CAG-based oracle evaluation?
CAG (context-augmented generation) oracle evaluation is a methodology where a separate oracle model is given the same context and question as your RAG system, and its output is used as a ground-truth reference for scoring. It avoids the need to manually label ideal answers while still capturing domain-specific quality.
How do I evaluate RAG retrieval without manually labelling relevant chunks?
Modern evaluation methods score retrieval quality indirectly, by testing whether the generated answer could plausibly have been derived from the retrieved context. If the answer is correct but the retrieved context does not support it, something is wrong with your retrieval. This avoids the expense of hand-labelling every question-chunk pair.
How often should I re-evaluate a RAG system in production?
Continuously on production traffic, not just offline on a fixed dataset. RAG pipelines drift when the underlying embedding model, the generation model, or the document corpus changes. Online evaluation catches drift that offline benchmarks miss.