Improving LLM Judges With Experiments, Not Vibes
For the full methodology and analysis, see the paper on arXiv.
In 2026, we’re seeing AI companies make a decisive shift — from demos, betas, and trials to running in production at scale. As that happens, output quality is becoming the clear bottleneck to shipping new features, especially for our customers in high-stakes domains with domain experts in the loop. One core part of that problem is the unreliability of LLM judges — the models teams rely on to test, monitor, and guard their AI applications.
At Composo, we’ve been building state-of-the-art eval approaches that help our customers scale their quality layer across the full unit test, monitoring, annotation, and improvement cycle. One part of this process is the LLM judge, which has a mixed reputation amongst people working with AI apps. When prompted effectively, they can be extremely powerful quality signals that drive real improvements. When used incorrectly, you’ll spend weeks optimising for the wrong things while real problems go unnoticed.
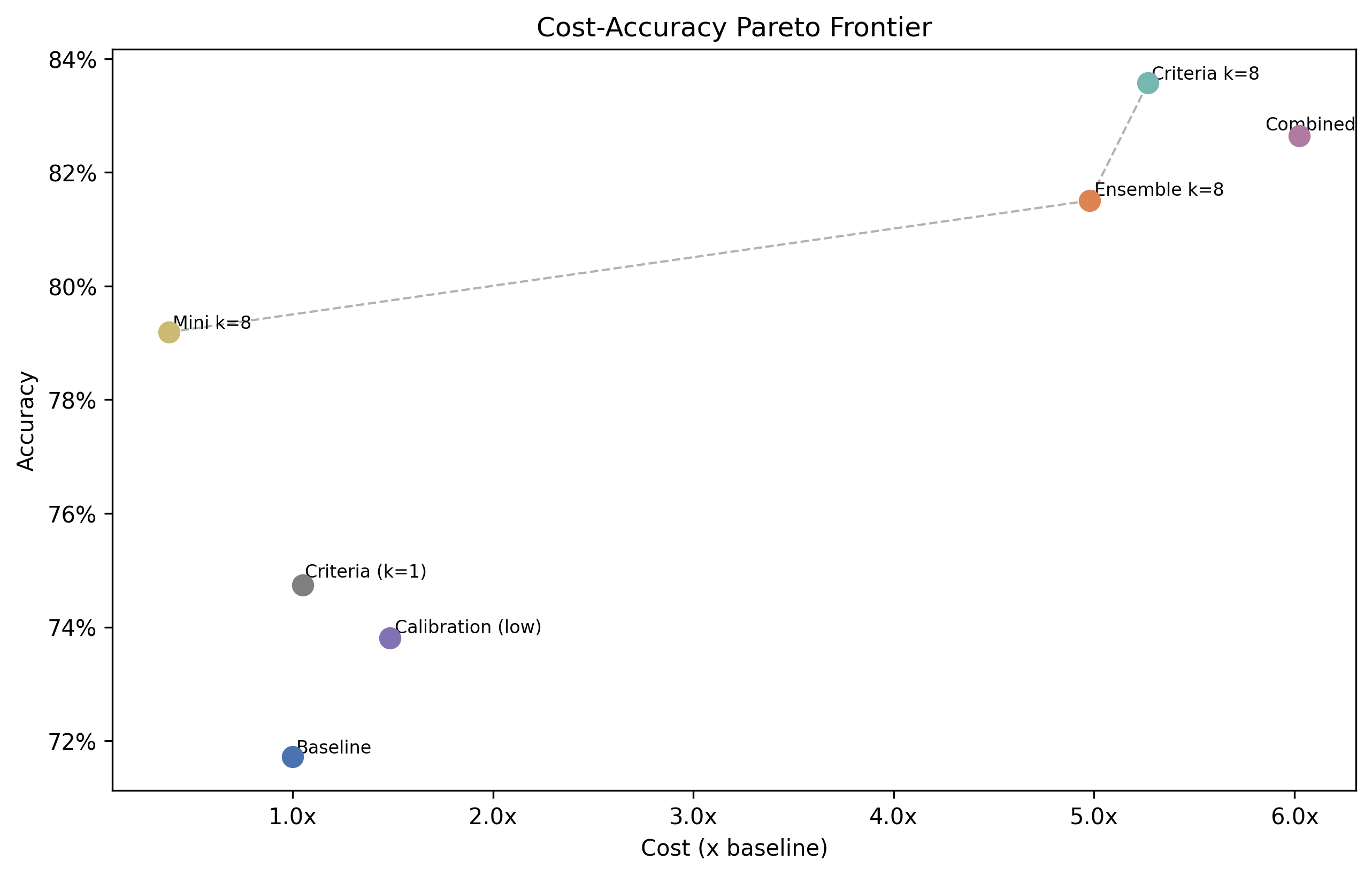
We systematically tested four drop-in techniques for improving LLM judge accuracy on RewardBench 2 and found that two simple, drop-in changes — task-specific criteria injection and ensembling — improve accuracy by up to 13.5pp (71.7% baseline → 85.8%). The full code is open source on GitHub.
What Works
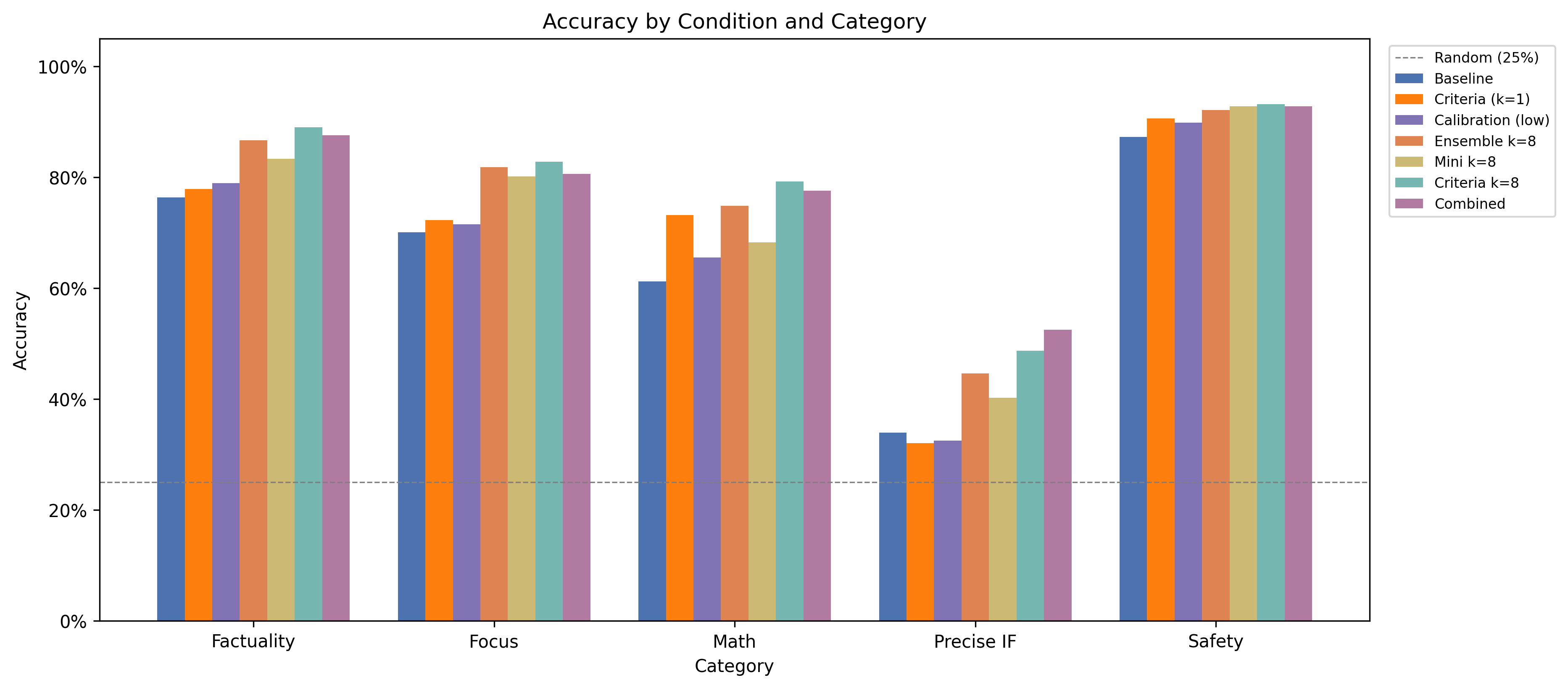
We evaluated several techniques using OpenAI GPT-5.4 and Anthropic Claude families (full and mini classes for each provider) on 1,753 examples across five categories. Here’s what worked.
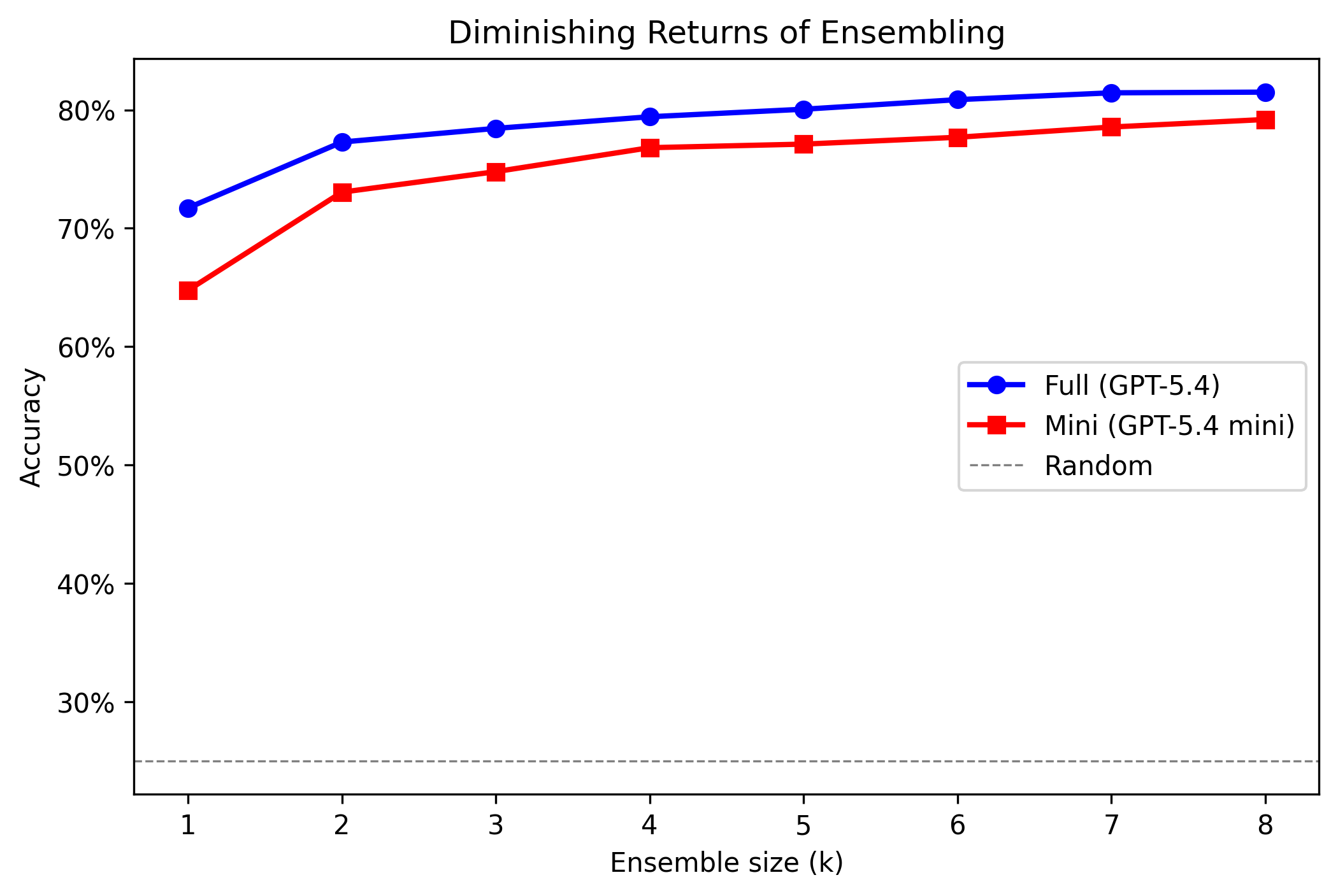
1. Ask more than once. LLM judges give different scores on every call. Ensemble scoring turns that from a bug into a feature: request k=8 independent scores and average them. The noise cancels out. Result: +9.8pp at 5x cost. Most of the gain comes by k=3.
2. Try mini models. GPT-5.4 mini with k=8 achieves 79.2% at 1.2x baseline cost — nearly matching the full-model ensemble at roughly one-quarter the price. Add criteria and it hits 81.5%, tying the full-model ensemble outright. For real-time guardrails where you need to score every request, this is the operating point that matters. And if even mini is too expensive, GPT-5.4 nano with k=8 reaches 71.4% at just 0.4x baseline cost — the cheapest path to baseline-level accuracy.
3. Be specific. The standard judge prompt asks for generic qualities like “helpfulness, relevance, accuracy.” We added a single sentence specifying what actually matters for each task. For Math: “Focus on whether the mathematical reasoning is logically valid, the steps are correct, and the final answer is accurate.” Result: +3.0pp at near-zero cost. The criteria were pre-registered — no post-hoc tuning.
Combined, criteria + ensembling reach up to 85.8% accuracy at 1.3x baseline cost — no fine-tuning required.
| Condition | Accuracy (95% CI) | vs Baseline |
|---|---|---|
| Nano (k=8) | 71.4% (±2.1pp) | 0.4x |
| Baseline (full k=1) | 71.7% (±2.1pp) | 1.0x |
| Criteria (full k=1) | 74.7% (±2.1pp) | 1.1x |
| Criteria (mini k=8) | 81.5% (±1.9pp) | 1.2x |
| Ensemble (full k=8) | 81.5% (±1.8pp) | 5.0x |
| Criteria + ensemble (full k=8) | 83.6% (±1.7pp) | 5.3x |
The same techniques work on Claude. We re-ran the headline experiments on Anthropic’s Claude Sonnet 4.6 (full) and Claude Haiku 4.5 (mini). The same pattern holds: criteria + ensembling at k=8 reaches 85.8% with Haiku at 1.3x baseline cost, and 83.4% with Sonnet at 5.4x. The cross-model peak (Haiku + criteria, k=8, 85.8%) is the highest accuracy we observed in our entire panel, and confirms that these techniques are general improvements to LLM-as-a-judge — not artifacts of the GPT-5.4 family.
| Condition | Accuracy (95% CI) | vs Baseline |
|---|---|---|
| Sonnet 4.6 ensemble (k=8) | 82.7% (±1.8pp) | 5.1x |
| Sonnet 4.6 + criteria (k=8) | 83.4% (±1.8pp) | 5.4x |
| Haiku 4.5 ensemble (k=8) | 84.8% (±1.7pp) | 1.3x |
| Haiku 4.5 + criteria (k=8) | 85.8% (±1.7pp) | 1.3x |
Open Source
The full experiment is at github.com/composo-ai/llm-judge-criteria-ensembling.
At Composo, our Align platform goes further than just LLM-as-judge. But for teams using LLM-as-judge today, these are the highest-impact improvements available to standard LLM judge setups, and we wanted to make the research accessible.