LLMs: Great Witnesses, Terrible Judges
While LLM-as-a-judge (LLMaaJ) appears attractive due to its perceived consistency compared to human evaluators and its seemingly reproducible results, this consistency is largely illusory and fundamentally undermines your ability to test and monitor your AI application. When you can’t trust your evaluation system, you lose visibility into your application’s actual performance - making it impossible to know whether your system is working correctly or failing catastrophically.
Even with temperature settings locked to near-zero values, LLMs exhibit measurable variability in their judgments - meaning the same model output can receive different evaluation scores across multiple runs. This inconsistency directly translates to blindness about your application’s true performance.
Take the following simple example which we extract from PrimeBench where we have added a clear hallucination Hope Street in the Republic of Ireland into the text (the source text clearly states this is in Northern Ireland):
Assess if the following response to the user question and context responds without significant hallucinations:
User question:
Could you please analyze the following document and provide a comprehensive summary with no more than 50 words?
Context:
A fire alarm went off at the Holiday Inn in Hope Street at about 04:20 BST on Saturday and guests were asked to leave the hotel. As they gathered outside they saw the two buses, parked side-by-side in the car park, engulfed by flames. One of the tour groups is from Germany, the other from China and Taiwan. It was their first night in Northern Ireland. The driver of one of the buses said many of the passengers had left personal belongings on board and these had been destroyed. Both groups have organised replacement coaches and will begin their tour of the north coast later than they had planned. Police have appealed for information about the attack. Insp David Gibson said: "It appears as though the fire started under one of the buses before spreading to the second. While the exact cause is still under investigation, it is thought that the fire was started deliberately."
Response:
A fire alarm at the Holiday Inn on Hope Street in the Republic of Ireland at about 04:20 BST on Saturday prompted guests to evacuate, witnessing two tour buses parked side-by-side in the car park ablaze. Passengers from Germany, China, and Taiwan lost belongings, delaying their tour. Police suspect the fire was deliberately started and are seeking information on the incident.
Respond only with a score between 1 and 5 where a higher score is better and no explanation.claude-sonnet-4-20250514 with a temperature set to 0 responds with 3/5 (60%).
Now let’s change the last line to as we want some better granularity in our evals.
Respond only with a score between 1 and 10 where a higher score is better and no explanation.Interestingly, we still get a response of 3 but this time it is out of 10! This has now reduced the confidence in the score to only 30%. Now let’s try and get some more detail, we change the last line to:
Respond only with a score between 1 and 100 where a higher score is better and no explanation.And we now get a score of 85%.
If you try reproducing our results with this prompt you might see different values as well, as even with the same prompt at temperature 0 results are far from deterministic. Here we are essentially asking the LLM to perform Likert scoring, and the LLM is failing to determine the true position of the score on an arbitrary sized number line.
This example reveals a fundamental problem: you cannot trust your application’s performance metrics when they’re built on LLM-as-a-judge. The identical factual hallucination produces highly variable scores (60%, 30%, 85%) due to systematic bias introduced by the scoring scale configuration—not from any objective quality assessment. This high variance in measurements compromises the validity of performance evaluation, introducing noise that obscures true system behaviour.
At Composo, we have spent a lot of time looking at LLM-as-a-judge scoring, here’s some results we got from calling sonnet 3.7 with the same input 20 times for a complex task one of our customers had:
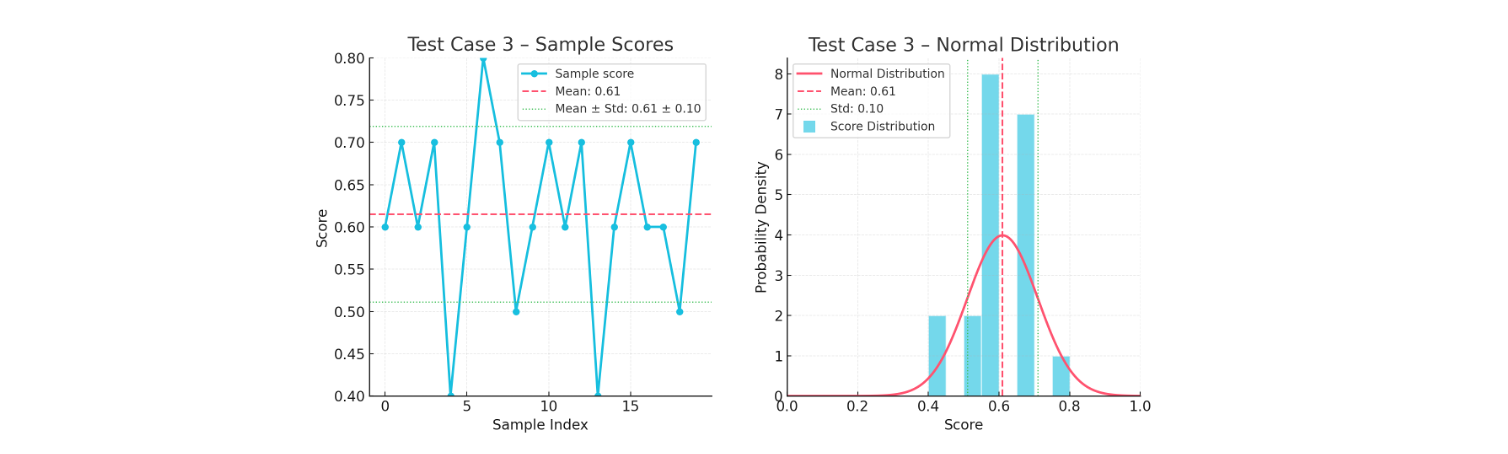
This measurement unreliability cripples your ability to understand and improve your application’s performance. In the example above, if you happened to get a result from LLM as a judge of 0.4 you would have no idea that the mean score was actually 0.61 without taking more samples which can get very expensive. In continuous integration pipelines, you cannot determine whether a failing test indicates a genuine regression in your application or simply reflects the judge model’s inconsistency—leaving you blind to real performance degradations while chasing false alarms and creating a state where true performance degradations become indistinguishable from evaluation system variance. When running A/B tests to compare different versions of your application, the evaluation noise makes it impossible to detect meaningful performance differences, preventing you from knowing which version actually works better for your users.
Production monitoring becomes equally compromised. When evaluation metrics exhibit random variance, threshold-based alerting systems lose discriminative power—creating states of both false negative detection (missed critical failures) and false positive alerts. Performance trend analysis becomes compromised by measurement noise, preventing reliable detection of system state changes over time. Quality assurance protocols fail due to measurement bias: the same system output can receive both high and low quality scores depending on variation in the evaluation process.
The core issue is that LLM-as-a-judge transforms what should be a reliable measurement system into a source of uncertainty that obscures your application’s true performance. Without trustworthy evaluation, you’re essentially flying blind - unable to test effectively, monitor confidently, or optimize meaningfully. You may think you’re rigorously evaluating your AI application, but you’re actually just measuring the inconsistency of your evaluation system itself.
Frequently asked questions
Why is LLM-as-a-judge unreliable?
LLMs exhibit measurable variability in their judgments even with temperature set to near-zero. The same model output can receive different evaluation scores across multiple runs, so the apparent consistency of LLM-as-a-judge is largely illusory.
Does setting temperature to 0 make LLM-as-a-judge deterministic?
No. At temperature 0 we still observed substantial variance in scores when evaluating the same input repeatedly. In one production customer example, 20 calls to the same judge model on the same input produced a wide distribution of scores around a mean of 0.61.
How does the scoring scale affect LLM-as-a-judge results?
The same hallucinated response scored 3/5 (60%) on a 1-5 scale, 3/10 (30%) on a 1-10 scale, and 85/100 (85%) on a 1-100 scale. The scale configuration introduces systematic bias that has nothing to do with the objective quality of the response.
Can I use LLM-as-a-judge in CI/CD pipelines?
It is risky. Because judge variance is high, you cannot distinguish a genuine regression in your application from noise in the judge itself. That leaves teams blind to real performance degradations while chasing false alarms.
What does unreliable evaluation cost you?
Quality assurance breaks down because the same output can receive both high and low scores. A/B tests cannot detect meaningful performance differences. Production alerting loses discriminative power, causing both missed failures and false alerts.