Composo Align achieves state-of-the-art performance in evals
Introduction
In the rapidly evolving landscape of LLM applications, reliable evaluation remains the critical bottleneck for deployment confidence. Current approaches—particularly using LLMs as judges—introduce significant uncertainty into development cycles, with inconsistent scores and poor correlation to real-world performance metrics.
At Composo, we’ve developed a fundamentally different approach - Composo Align. Underpinned by a generative reward model architecture, it provides deterministic, consistent scoring that enables teams to quantify improvements with confidence. Here we outline how we’ve validated our approach across both internal customer datasets and real-world benchmarks that matter for production applications.
The Evaluation Challenge
When we talk to engineering and product teams, we consistently hear the same pain points:
- “Human ‘vibe-checks’ on quality are costly & don’t scale”
- “LLM as a judge is unreliable & doesn’t work for many use cases”
- “How does changing prompts or models impact my application?”
- “Our customers need us to show high accuracy & quality”
Why LLM as a judge falls short
- Cannot provide precise, quantitative metrics
- Unreliable, inconsistent scoring (the same response might receive 0.7 one minute and 0.5 the next)
- Poor correlation with actual business metrics
- Extensive optimization is required to clearly define evaluation criteria & scoring rubrics
- Expensive, slow & difficult to scale
LLM-based evaluations can be adequate in scenarios where high-level checks suffice for your needs. They’re a reasonable option when you don’t require reliable, quantitative results for decision-making and when you have time to invest in optimizing the evaluation process.
However, if quality of application outputs is a crucial factor for you, you’ll need to look beyond standard LLM as a judge approaches. Alternatives like Composo become essential when you need evaluation results you can truly trust and depend on. These solutions are particularly valuable when you want a system that’s quick to implement, and straightforward to use, eliminating the complexity and inconsistency inherent in traditional LLM-based evaluation methods.
Composo Align: The Alternative to LLM as a judge
Composo is the alternative to LLM-as-a-judge, which:
- Gives you results you can trust: Our scores are precise, deterministic & accurate
- With minimal work: Just type a single sentence to create any custom criteria
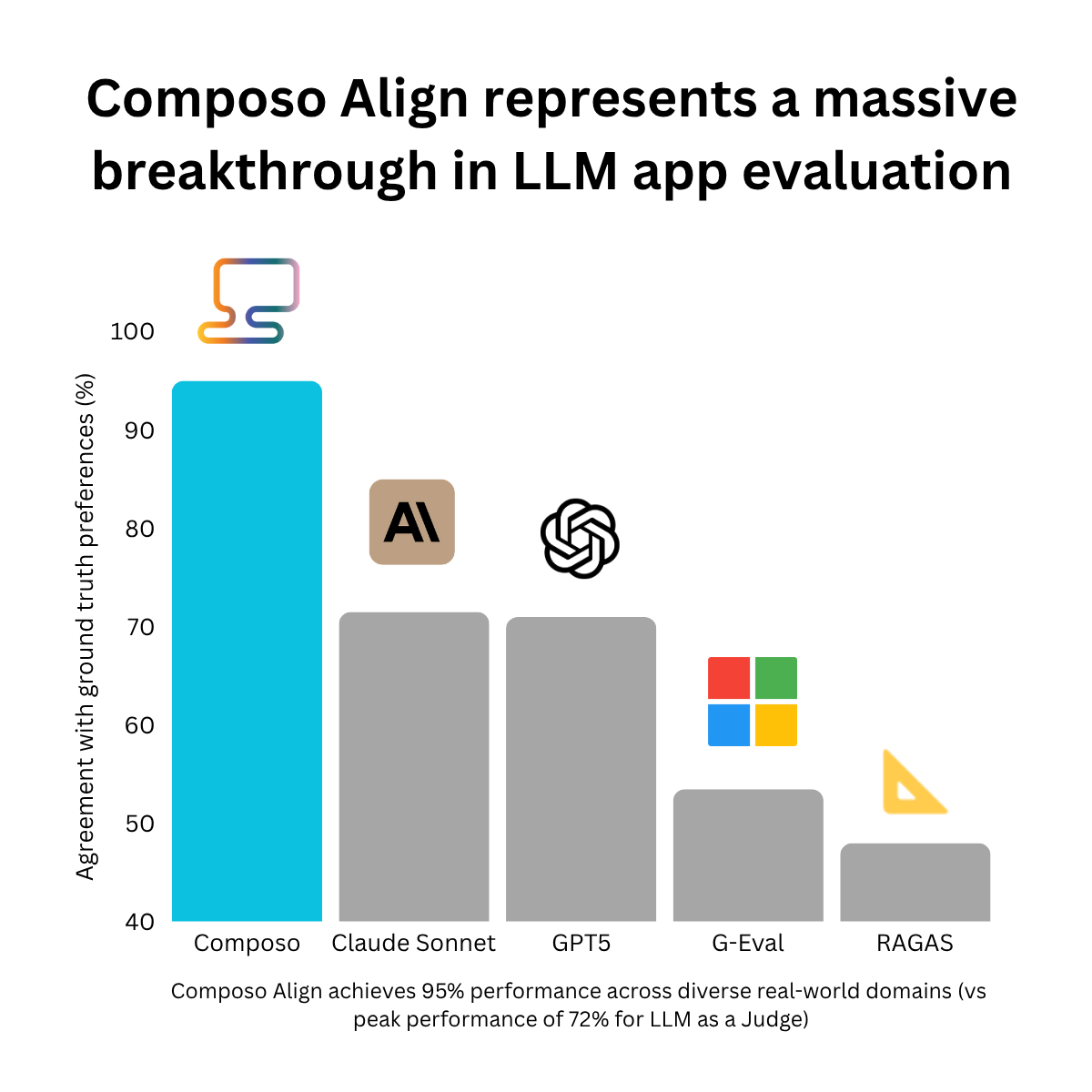
Composo Align achieves outstanding performance compared to the next best state of the art evals:
- 95% performance vs 72% for all SOTA LLM as a judge based evals (71.5% for Claude Sonnet, 71.0% for OpenAI’s GPT5, 53.5 for G-Eval & 47.7% for RAGAS)
- 70% reduction in error rate over LLM as a judge
In addition, Composo’s architecture makes its scoring deterministic, resulting in 100% consistency & repeatability of scores. LLM as a judges on the other hand demonstrate significant variation when evaluating the exact same datapoints.
Our Validation Methodology
Academic benchmarks don’t translate to business needs:
- Focus on artificial tasks rather than real-world business use cases
- Don’t cover diverse domains relevant to actual applications
- Fail to measure dimensions that impact business value
Instead of relying on artificial benchmarks, we’ve validated our generative reward model approach using methodologies focused on real-world applicability. In doing so we can demonstrate how our model performs in actual production environments, delivering consistent scores aligned with business metrics.
Enter PrimeBench: Practical Real-world Industry & Multi-domain evaluator benchmark
Our primary validation instrument, the PrimeBench benchmark, was constructed to address the limitations of conventional academic evaluation methods. This curated dataset integrates diverse domain-specific challenges in real-world industry tasks ranging from finance to healthcare, news summarisation & customer support.
It incorporates data from a range of sources, such as:
- FinQA: Financial corpus requiring numerical reasoning & domain knowledge
- TechQA: Technical support inquiries with specialized terminology
- PubmedQA: Medical information assessment demanding scientific accuracy & precision
- XSum: Text summarization tasks evaluating information preservation, conciseness & relevance
PrimeBench contains complex queries that reflect actual business scenarios requiring domain expertise, contextual understanding, and retrieval capabilities. Each domain presents unique challenges that test different aspects of model performance:
Financial Analysis (FinQA):
- “What portion of total purchase price is related to stock awards?” - Requires numerical reasoning, financial document comprehension, and extraction of specific financial metrics.
Medical Research (PubMedQA):
- “Are group 2 innate lymphoid cells (ILC2s) increased in chronic rhinosinusitis with nasal polyps or eosinophilia?” - Demands scientific precision, biomedical terminology understanding, and ability to synthesize research findings.
Technical Support (TechQA):
- “Can you help me find a list of all the versions and fixpacks of the ITCAM Agent for Datapower and where can I download it?” - Tests product knowledge, technical documentation retrieval, and practical resource identification.
XSum (Cross-domain):
- “What are the emerging geopolitical risks facing European technology companies in 2025?” - Evaluates synthesis of current events, industry trends, and concise fact preservation.
These examples illustrate why effective evaluation requires a benchmark that is able to assess response quality in contexts that matter to businesses, where use cases span multiple knowledge domains and contain detailed contexts from complex, proprietary knowledge sources.
Supplemental Real-World Validation
Beyond our publicly available benchmark dataset, we supplemented our analysis with anonymized production data from consenting enterprise partners across multiple sectors. These datasets represent authentic customer interactions and business use cases from organizations that have implemented our evaluation framework.
This real-world corpus provides a critical validation layer that confirms our findings generalize to production environments with actual business metrics and success criteria.
Comparative Methodology Against State-of-the-Art Judges & RAGAS
To establish a comprehensive performance baseline, we evaluated Composo Align against the most advanced LLM-as-judge implementations available as of May 2025 & RAGAS. Our comparison utilized the following models, both configured with specialized judgement prompts optimized for evaluation task:
- Claude 3.7 Sonnet: Anthropic’s latest reasoning-focused model
- GPT-4.1: OpenAI’s latest flagship model
- RAGAS (powered by GPT4.1 as the judge LLM)
For each test case in both PrimeBench and our supplemental datasets, we conducted pairwise comparisons between Composo Align and these state-of-the-art LLM judges.
You can find the PrimeBench dataset here & implementation for replication here.
How To Use Composo Align
Continuous and binary scoring options
- Reward Score Evaluation: Fine-grained assessments (0-1) based on custom criteria
- Binary Evaluation: Simple pass/fail assessments for safety and compliance
Simple, single sentence criteria
A key advantage of our approach is dramatic simplification of the evaluation process. While LLM judges require complex prompt engineering, our generative reward model needs only a single-sentence criterion.
For example, to evaluate empathy in customer support responses, you simply define:
- “Reward responses that express appropriate empathy if the user is facing a problem they’re finding frustrating”
Or to evaluate faithfulness:
- “Reward responses that strictly only use information from the provided context”
This simplicity enables:
- Rapid implementation without specialized ML expertise
- Easy customization for domain-specific requirements
- Flexibility to evaluate across multiple dimensions
One model with flexibility across all use cases
- Context window: 128k tokens supported (approximately 500 pages)
- Language support: All major languages for both text and code evaluation
- Advanced capabilities: Supports agent evaluation, function calling & reasoning
- Deployment options: Cloud API and on-premise solutions available
- Performance: Works exceptionally well across domains with no fine-tuning required (though custom fine-tuning is available for specialized use cases)
Conclusion: Evaluation You Can Trust
The path to production-ready LLM applications requires evaluation metrics teams can trust. Our generative reward model approach delivers precisely this: consistent, deterministic scores that enable confident development decisions.
By focusing our validation on real-world datasets and applications rather than artificial benchmarks, we’ve demonstrated superior performance where it matters most—in the complex, diverse domains where LLMs are actually deployed.
For teams building LLM applications, this means:
- Accelerated development cycles with reliable metrics
- Clear insight into performance improvements
- Confidence in production deployments
- Simplified implementation without extensive prompt engineering