The Complete Guide to Evaluating Tools & Agents
Introduction
As LLM applications evolve into sophisticated agentic systems, function calling and multi-step reasoning have emerged as critical capabilities for building production-ready applications. Yet evaluating these complex behaviors remains one of the thorniest challenges in LLM development. Traditional LLM-as-judge approaches struggle with inconsistent scoring and poor correlation with real-world performance.
At Composo, we’ve developed a component-based evaluation framework that addresses these challenges head-on, leveraging our generative reward model technology to deliver deterministic, reliable evaluation metrics that teams can actually trust.
Modern agentic LLMs operate through multiple interconnected components:
- Reasoning and planning through thinking tokens or internal deliberation
- Function calling to interact with external tools and data
- Response generation that synthesizes information into coherent outputs
- Multi-step workflows that chain these components together
Effective evaluation requires analyzing each component individually while understanding how they work together as a system.
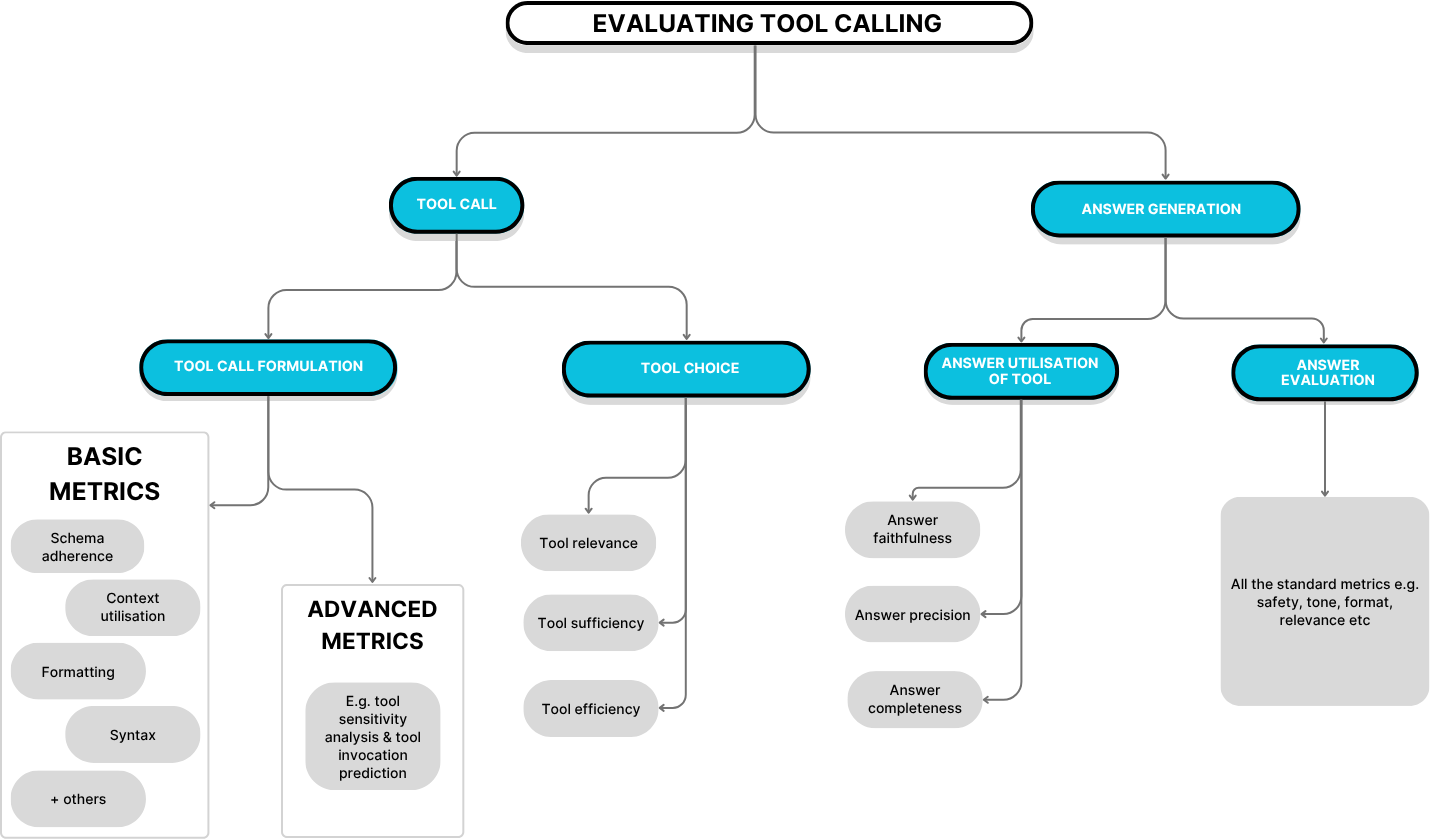
The Function Call Pipeline
When evaluating LLM function calls specifically, it’s crucial to recognize that we’re actually evaluating two distinct LLM steps:
- The LLM decides to make a function call (based on user input)
- The LLM uses the function return to generate a response (when applicable)
The function execution itself sits between these steps but isn’t part of the LLM evaluation challenge. Here’s the complete pipeline:
- A: User input/query (or possibly an input from a previous step in LLM workflow)
- B: LLM makes function call(s)
- C: Function returns result(s)
- D: LLM produces final output (note: this step may not occur if the function return is the final result)
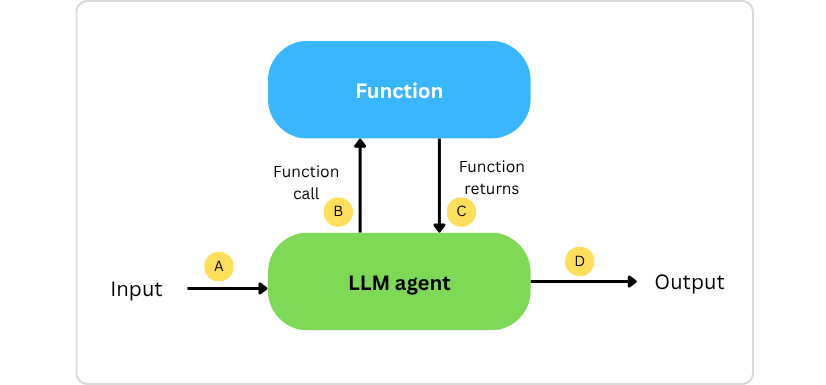
The Component-Based Evaluation Framework
1. Tool Call Formulation (how a tool is used)
In the pipeline above, this is evaluating B given A (though in practice, we recommend providing A, B, C, and D to Composo for improved evaluation accuracy).
At this stage, we evaluate whether a function call was formulated correctly (or in other words, have the right arguments been used, and has appropriate information been included within those arguments)? For example:
- Arguments are formulated using only context given by user
- Optional arguments have been selected appropriately to give sufficient specificity
- For an email search, ensure that all possible folders, date ranges and user search terms are attempted
- Has sufficient context from user been provided in arguments
Composo’s generative reward models can effectively evaluate formulation quality with criteria such as:
"Reward tool calls that only include information from the user's query"
Or for context utilization:
"Reward tool calls that extract and use all relevant entities mentioned in the user's query as appropriate parameters"
While these evaluations can’t determine if the right function was called, they ensure technical correctness and proper parameter extraction — critical prerequisites for successful function execution.
*Important Implementation Note: While this evaluation conceptually focuses on B given A, in practice you should provide Composo with all available information (A, B, C, and D) when running these evaluations. The additional context from function returns and final outputs significantly improves the evaluation’s ability to assess whether parameters were formulated optimally.
2. Tool Choice (which tools are used)
With the benefit of hindsight, evaluators gain significant information advantage. We can now evaluate the choice to use a tool (i.e. B, given A, C & D). We divide this into 2 metrics:
- Tool relevance: Were the right tools chosen for the task?
- Tool sufficiency: Were enough tools called to complete the task?
This is where evaluation truly shines. By seeing what the function returned and how it was used, evaluators gain significant leverage over the original LLM choosing which tool to use. This can be implemented in Composo with criteria such as:
For tool relevance:
"Reward tool calls that retrieved information relevant to answering the user's query"
For tool sufficiency:
"Reward tool calls that retrieved all necessary information for comprehensive answer generation"
Or additionally, for tool relevance:
"Penalize tool calls retrieved superfluous or unnecessary information"
Furthermore, advanced criteria can capture domain-specific patterns, e.g. in medical contexts:
"Reward tool calls that retrieve local guidelines & drug formularies that are up to date when providing medical dosing information"
In finance or data analysis:
"Reward tool calls that retrieve both current and historical data when the user asks about trends or changes"
For customer support:
"Reward tool calls that check user account status before attempting order-specific lookups"
3. Response Integration Quality
Here we evaluate how well the LLM uses the function returns, similar to how we evaluate generation quality in RAG systems, this is the quality of D, given A & C:
- Answer faithfulness to tool returns: Does the response accurately reflect the function results?
- Answer completeness to tool returns: Did the LLM use all necessary information from the returns?
- Answer precision to tool returns: Did the LLM include only the relevant information without extraneous details?
For faithfulness:
"Reward responses where all claims are directly supported by the tool call returns without hallucination or speculation beyond the provided data"
For completeness:
"Reward responses that incorporate all relevant information from tool call returns needed to comprehensively answer the user's question"
For precision:
"Reward responses that include only the specific information from tool call returns that directly addresses the user's query, avoiding tangential details"
4. Output Quality
Here, independent of tool calls we evaluate D given A, on a range of quality dimensions. This evaluation ensures that regardless of how information was obtained, the final response meets quality standards.
Comprehensive output evaluation can span any custom dimension, including safety, tone, formatting, content quality, and domain-specific requirements.
5. Reasoning and Thinking Evaluation
For agentic systems that expose reasoning traces or thinking tokens, evaluating the quality of deliberation becomes crucial. This component evaluates the LLM’s internal reasoning process before it makes decisions about tool usage or response generation.
Key evaluation criteria for reasoning quality include:
For logical coherence:
"Reward reasoning traces that follow clear logical steps without contradictions or unsupported leaps in logic"
For comprehensive consideration:
"Reward reasoning that systematically considers multiple approaches or solutions before settling on a final decision"
For acknowledging limitations:
"Reward reasoning that explicitly acknowledges when information is missing or uncertain and articulates what additional data would be helpful"
For goal alignment:
"Reward reasoning that maintains clear focus on the user's original objective throughout the deliberation process"
For efficiency:
"Penalize reasoning that includes repetitive thoughts or unnecessarily verbose deliberation that doesn't add value to the decision-making"
Additional domain-specific reasoning criteria might include:
In analytical contexts:
"Reward reasoning that breaks down complex problems into manageable sub-components before attempting to solve them"
In safety-critical applications:
"Reward reasoning that explicitly considers potential risks or failure modes before proposing actions"
6. Full System-Level Analysis
While component-level evaluation provides detailed insights, agentic systems also require holistic evaluation through composite metrics that reveal system-wide patterns and failure modes.
Core System Metrics: At the highest level, agentic systems must be evaluated on their fundamental purpose:
- Goal Success Rate: Does the agent achieve the user’s intended outcome?
- Task Completion Rate: Does the agent successfully complete all required steps?
These top-level metrics are essential but insufficient on their own — when an agent fails, you need to understand why. This is where composite metrics become invaluable.
Composite Metrics Approach: Rather than evaluating the entire agent as a monolith, effective system-level analysis combines component metrics to identify where breakdowns occur:
- Goal Success Breakdown: Trace failures back to specific components
- Failed due to incorrect tool choice (Tool Choice metrics)
- Failed due to malformed function calls (Tool Call Formulation metrics)
- Failed due to poor reasoning (Reasoning Evaluation metrics)
- Failed due to incorrect use of tool returns (Response Integration Quality metrics)
- Task Completion Analysis: Understand partial successes and failure points
- Which subtasks are consistently completed vs. failed?
- Where in multi-step workflows do agents get stuck?
- Are failures due to error propagation or independent component issues?
- Efficiency Metrics that balance quality with resource usage:
- Token usage per successful task completion
- API calls per goal achievement
- Time to completion distributions
- Cost per successful outcome
- Robustness Indicators that measure consistency:
- Success rate variance across similar inputs
- Failure mode clustering and patterns
- Recovery ability from component-level errors
Example implementations with Composo would involve full system level metrics such as:
"Reward traces where all required information was gathered and correctly integrated into the final response"
"Reward traces that reached their goal with the minimum necessary tool calls and no redundant operations"
These system level & composite metrics provide a bird’s-eye view of your agentic system, helping you quickly identify whether issues stem from poor reasoning, incorrect tool choices, bad parameter formulation, or integration failures. By connecting goal success rates to component-level evaluations, you can rapidly diagnose and fix the root causes of agent failures.
We’ll be publishing more comprehensive research on system-level agent evaluation methodologies in the coming weeks, including advanced techniques for multi-agent systems and long-running agentic workflows.
Invocation Observability and Optimization
Beyond the core evaluation components, you can gain deeper insights by analyzing the patterns in your Tool Choice metrics. Specifically, the relationship between tool sufficiency and tool relevance scores reveals critical optimization opportunities for your function calling system.
Understanding the Sufficiency-Relevance Tradeoff
The tool sufficiency and tool relevance metrics from your Tool Choice evaluation naturally exist in tension:
- High Tool Sufficiency: Tools are consistently called when needed (few missed opportunities)
- High Tool Relevance: Tools are only called when they add value (few unnecessary calls)
By analyzing the ratio and distribution of these metrics across your evaluation data, you can identify systematic patterns in how your LLM makes tool invocation decisions. This analysis reveals that LLMs manage tool invocation through implicit sensitivity thresholds — the point at which they decide a tool is worth calling.
Sensitivity Threshold Analysis
Using your existing Tool Choice metrics, you can perform valuable threshold analysis:
Individual Tool Sensitivity Patterns: By examining sufficiency and relevance scores for each tool, you can identify tools that are:
- Over-sensitive (high sufficiency but low relevance — called too frequently)
- Under-sensitive (low sufficiency but high relevance — missed when needed)
Cross-Tool Dependencies: Analyzing metric patterns across multiple tools reveals:
- Tools that should typically be called together
- Tools that become redundant after another is invoked
- Cascading dependencies in multi-tool workflows
Optimization Insights: This analysis of your evaluation metrics helps you:
- Understand the current sufficiency-relevance tradeoff for each tool
- Identify which tools need threshold adjustments
- Monitor how prompt or configuration changes affect the balance
- Track improvements in overall system performance
The key insight is that unlike other quality dimensions where you can improve both aspects simultaneously, tool invocation is inherently classificatory — you’re always trading sufficiency for relevance or vice versa. Your evaluation metrics help you find the optimal balance for your specific use case.
Historical Learning for Custom Tool Models
For teams seeking to push beyond threshold tuning, there’s an advanced approach that leverages your evaluation data to train custom tool invocation models. This method uses your historical evaluation results to teach a model which tools are actually useful in your specific context.
The Historical Learning Framework:
- Data Collection: Gather comprehensive historical data showing:
- Times when the agent invoked a function call (A -> B)
- The function return values (C)
- How the results were used in the final response (D)
- Reasoning traces when available
- Outcome Labeling: Use your existing evaluation metrics (or additional labeling) to determine:
- Whether each function call contributed positively to the response quality
- The relative value of different tool invocations for similar queries
- Patterns in successful vs. unsuccessful tool usage
- Custom Model Training: Train a specialized model that learns from your evaluation data:
- This model can outperform general-purpose LLMs because it’s trained on your specific tool usage patterns
- It learns which queries truly benefit from which tools in your domain
- It captures optimal invocation sequences unique to your use case
Benefits of the Historical Approach:
- Domain Specificity: The model learns patterns specific to your tools and use cases
- Empirical Grounding: Decisions are based on actual historical performance from your evaluations
- Continuous Improvement: As you collect more evaluation data, the model becomes increasingly accurate
- Reduced Costs: Better tool selection can significantly reduce unnecessary API calls
Implementation Guide
Step 1: Start with High-Impact Evaluations
Begin where evaluation provides the most immediate value and insights:
Response Integration Quality (D given A & C)
- Implement faithfulness, completeness, and precision checks
- These evaluations have strong impact and immediate value
- Use simple, single-sentence criteria in Composo
Output Quality (D given A)
- Add comprehensive quality checks across all relevant dimensions
- Start with safety and basic quality, then add domain-specific criteria
- These work independently of function calling complexity
Step 2: Add Tool Analysis and Technical Validation
Once basic evaluation is working, add powerful tool selection analysis alongside technical checks:
Tool Choice (B given A, C & D)
- Evaluate tool relevance, sufficiency, and efficiency
- Requires logging function returns alongside calls
- Provides insights into systemic tool selection issues
Tool Call Formulation (B given A, C & D)
- Implement schema validation and parameter checking
- Remember to provide all available context to Composo for best results
- Essential for production reliability
Step 3: Expand to Full Agentic Evaluation
For teams building sophisticated agentic systems:
Reasoning and Thinking Evaluation
- Implement evaluation criteria for logical coherence and comprehensive consideration
- Monitor how reasoning quality affects downstream tool choices
- Use insights to improve prompting and model selection
System-Level Analysis
- Build composite metrics from your component evaluations
- Track error propagation and identify systemic issues
- Use bird’s-eye view metrics to guide optimization priorities
Step 4: Implement Advanced Optimization
Sensitivity Threshold Tuning
- Analyze the ratio of sufficiency to relevance scores from your Tool Choice metrics
- Identify optimal thresholds for each tool based on your use case requirements
- Monitor cross-tool dependencies and adjust accordingly
Historical Learning Implementation
- Leverage your accumulated evaluation data across all components
- Train custom models for superior tool invocation and reasoning
- Continuously improve based on new evaluation results
Conclusion
As LLM applications evolve into sophisticated agentic systems, evaluation must evolve too. By implementing our component-based evaluation framework — covering Tool Call Formulation, Tool Choice, Response Integration Quality, Output Quality, and Reasoning Evaluation — you gain comprehensive visibility into every aspect of your system’s performance.
Start with Response Integration Quality and Output Quality evaluations that provide immediate value, then systematically add Tool Call Formulation checks and Tool Choice analysis. For agentic systems, incorporate Reasoning Evaluation and build composite metrics for system-level insights.
Use the patterns in your evaluation data to optimize tool invocation thresholds, and for advanced teams, train custom models based on your historical performance.
With Composo’s generative reward models providing deterministic, reliable scoring at each component, you can build agentic applications with confidence.
Ready to transform your LLM evaluation? Try Composo Align today and experience the difference that deterministic, reliable evaluation can make for your agentic applications.